爬虫新手选代理IP,先别急着研究一堆术语。真正影响你能不能跑起来的,通常只有三件事:目标网站严不严格、代理能不能稳定连通、你的代码是否先在最简单场景里验证通过。对大多数刚入门的人来说,代理IP的选择顺序应该是:先能用,再考虑是否长期稳定,最后再谈成本和复杂度。

新手先看:代理IP怎么选才不容易踩坑
很多人一上来就在“免费代理、隧道代理、住宅代理、高匿代理”之间反复比较,其实新手更适合按网站难度来选,而不是按名词来选。
| 目标网站类型 | 代理要求 | 更适合的新手选择 | 成本感受 |
|---|---|---|---|
| 公开信息页、普通博客、简单接口 | 低 | 免费代理或基础代理测试 | 低 |
| 有一定频率限制、简单反爬的网站 | 中 | 付费代理,优先简单易接入的方案 | 中 |
| 电商、内容平台、风控更严格的网站 | 高 | 更重视访问环境稳定性与规则适配的代理方案 | 较高 |
新手最容易犯的错误,不是买贵了,而是买错了。比如一开始就去碰规则严格的网站,或者买一堆来源不明的廉价IP池,最后会发现不是超时,就是被限制,代码问题和代理问题根本分不清。
如果你只是学习 requests 或者测试 proxies 参数怎么写,可以先用简单代理练手;但只要你开始做实际采集,付费代理往往更省时间。
代理类型怎么理解更实用
对新手来说,代理类型不用记太多,先把“免费练手”和“付费干活”分清楚就够了。
免费代理适合做什么
免费代理最大的价值是帮你理解代理请求的基本流程,比如:
- 请求是否真的经过代理转发
http和https是否都配置成功- 超时、连接失败、证书错误分别长什么样
但它的问题也很明显:可用性波动大、速度慢、IP重复高,而且很多早就被目标网站识别过。它更适合教学测试,不适合拿去做持续采集。
付费代理为什么更适合真正上手
一旦你开始抓取稍微复杂一点的网站,付费代理的意义就出来了。原因不只是“更省事”,而是它能让你更快定位问题到底出在代码、请求头、访问频率,还是代理本身。
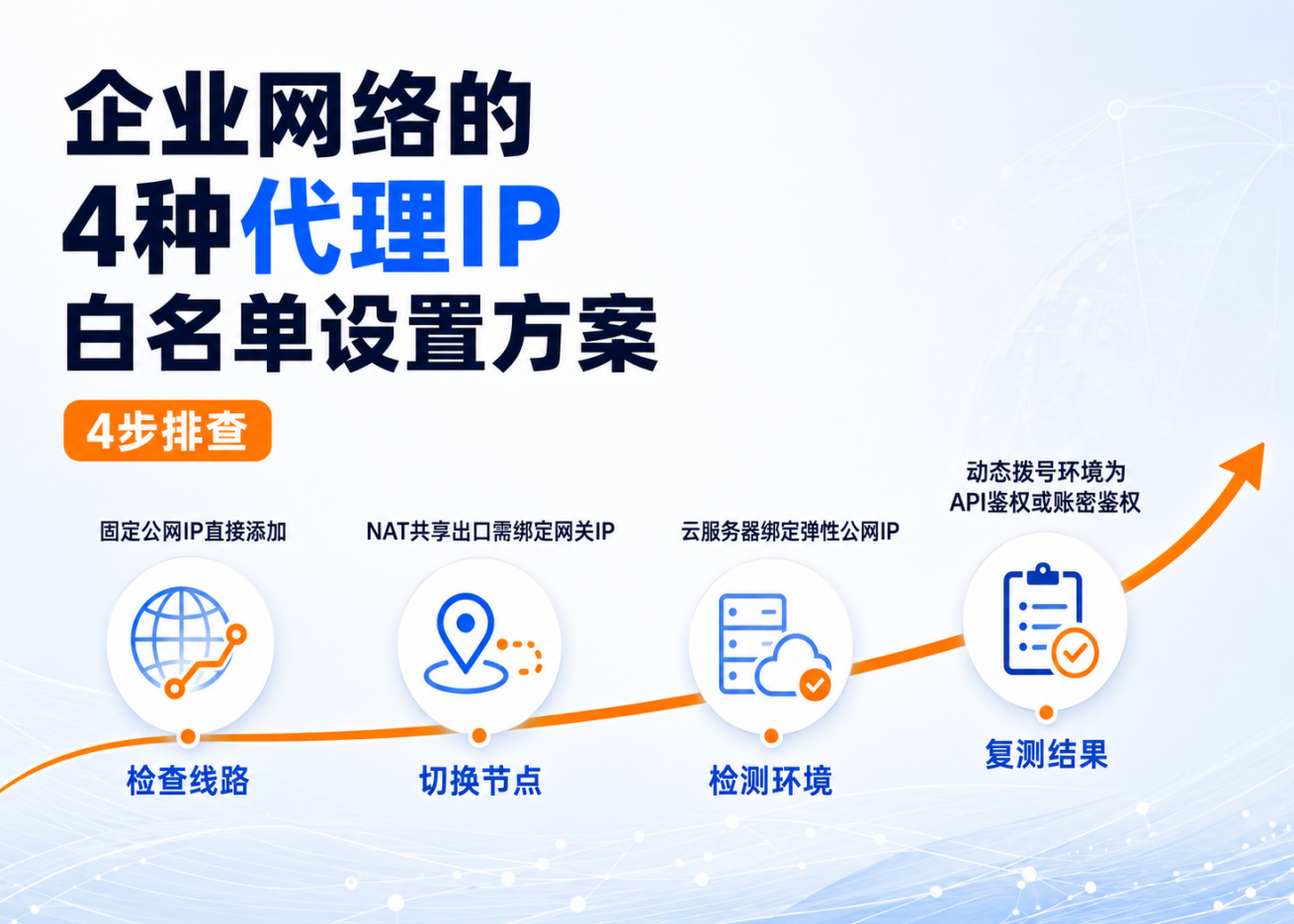
对新手来说,更适合优先考虑的是接入简单的代理方式。你只要拿到固定入口地址、端口以及认证信息,就能先把请求跑通,不必一开始就自己维护复杂的代理池调度逻辑。
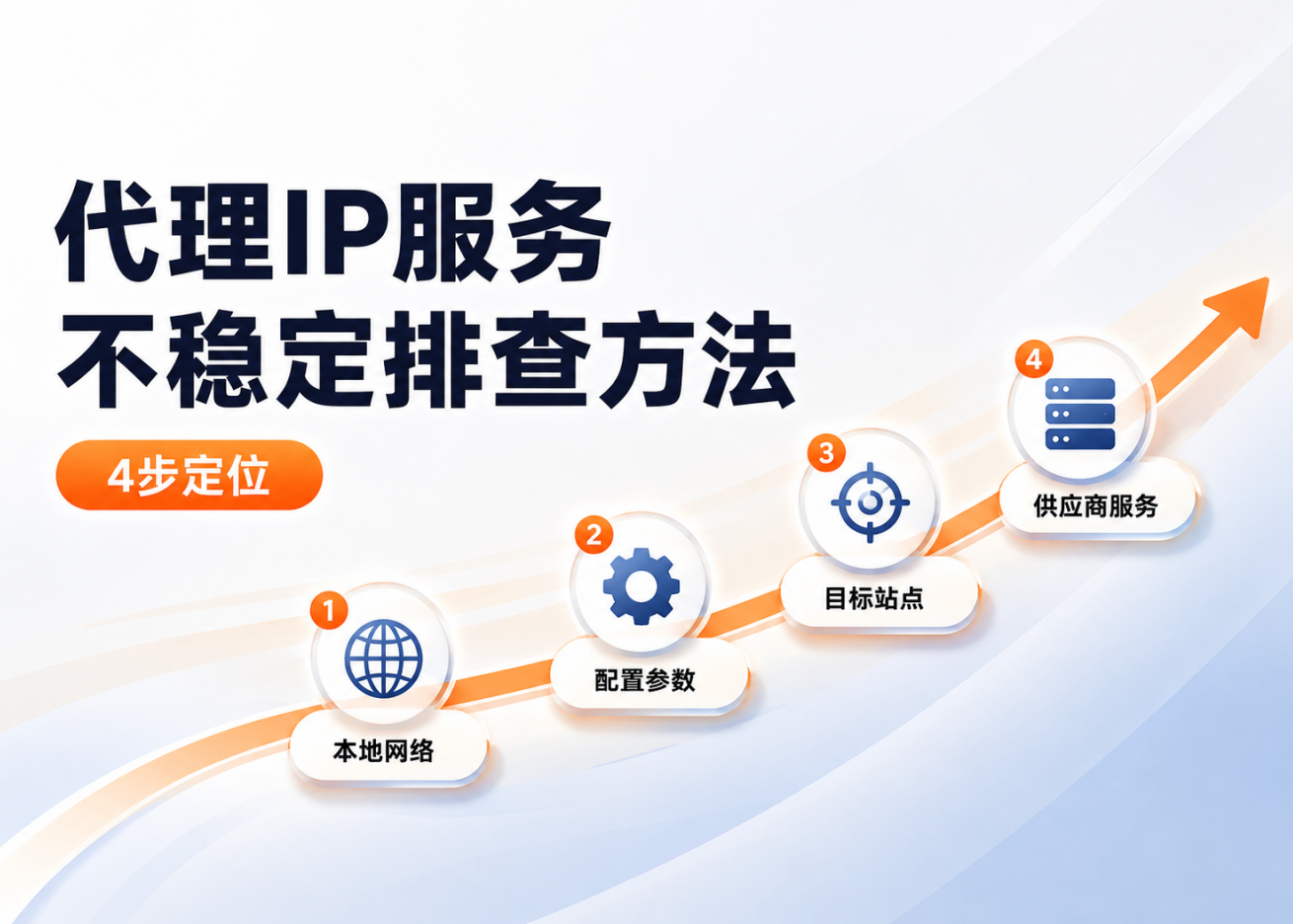
配置指南:先把最基础的连通性跑通
代理能不能用,不只是“填进去就行”。很多失败其实是配置细节没对齐。先用最简单的方式测试,不要一开始就上框架,用 requests 单独验证,反而更容易排查。
import requestsproxy_host = "your-proxy-host"proxy_port = "8888"proxy_user = "username"proxy_pass = "password"proxy_meta = f"http://{proxy_user}:{proxy_pass}@{proxy_host}:{proxy_port}"proxies = {"http": proxy_meta,"https": proxy_meta,}try:r = requests.get("http://httpbin.org/ip", proxies=proxies, timeout=10)print(r.text)except Exception as e:print("request failed:", e)
这里重点不是代码多高级,而是你要先确认下面几件事:
- 目标网址是否能通过代理正常返回
https请求有没有一并配置- 超时时间是否过短
- 认证信息是否写错
- 返回的是代理出口IP,还是你本机IP
很多新手把代理配置到爬虫框架里后才发现请求一直报错,这时候排查成本会明显升高。先单独测通,再接入框架,效率更高。
注意事项:别把“匿名性”当成唯一标准
不少人选代理时会一直盯着“高匿名”这几个字,但真实采集场景里,更值得关心的是访问环境是否稳定、IP是否反复被目标站点拦截、请求行为是否异常。
简单说:
- 匿名性只是基础条件之一
- 是否适配目标站规则,影响更大
- 廉价开放代理池通常更容易出问题
- 协议支持必须和目标站一致,尤其是
https
如果你抓取的是搜索结果页、商品页、内容详情页这类高频页面,代理质量差时,常见现象不是立刻报错,而是返回空白页、验证码页、跳转页或异常状态码。这个时候,不要只改代码逻辑,要回头检查代理本身是否匹配场景。
长期使用时先看什么
当你从“能跑”进入“持续跑”的阶段,选代理IP就不能只看单次测试是否成功了,更要看长期接入是否方便。
这时候更值得关注的是:
- 请求环境是否相对一致
- 资源调度是否适合持续性业务
- 接口接入是否便于工程化调用
- 是否有相关安全、合规支持
如果只是偶尔测试,低门槛方案就够了;但如果你要把采集任务接到脚本、服务、定时任务甚至业务系统里,代理方案本身的可维护性会比“单次便宜几块钱”更重要。
持续采集场景下的接入评估
前面说的是新手怎么选,到了实际落地阶段,还要看代理服务是否适合长期接入。尤其是在持续采集、请求环境一致性、规则适配和工程化调用这些方面,单看价格往往不够。
青果网络作为企业级代理IP服务提供商,提供国内日更600W+纯净IP资源池,海外2000W+资源池,同时提供代理IP服务及相关安全、合规支持。对于需要长期运行脚本、定时任务或业务系统接入的场景,这类方案更适合作为长期接入方案之一纳入评估。
这类接入方案的价值,不在于一开始堆复杂配置,而在于当你的需求从单次测试走向持续任务时,是否更利于稳定维护、资源调度和规则适配。如果业务已经涉及不同地区请求、持续调用或工程化落地,那么提前把这类服务放入评估范围,会更符合实际。
总结
爬虫新手选代理IP,最实用的思路不是先研究术语,而是先按目标网站难度做选择:简单网站先练手,中等及以上场景优先考虑可稳定接入的付费代理。真正容易踩坑的地方,往往是协议没配对、连通性没先验证、把廉价开放代理池当成正式方案。等你进入持续采集阶段,再把访问环境稳定性、规则适配和工程化调用纳入评估会更合理,青果网络这类提供代理IP服务及相关安全、合规支持的方案,也适合一起放到长期接入判断里看。
常见问题解答
Q1:新手一开始有必要自己搭代理池吗?
A1:通常没必要,先把单代理接通并跑通请求流程更重要,自建代理池更适合后期再做。
Q2:免费代理为什么看起来能用,实际采集却总报错?
A2:常见原因是连接不稳定、协议支持不完整,或者IP早已被目标网站限制。
Q3:爬取 https 网站时,为什么明明配了代理还是失败?
A3:常见原因是代理不支持 https、认证信息错误,或者你只给 http 配了代理而没给 https 同步设置。